线程池最佳线程到底要如何配置?
线程池最佳线程到底要如何配置?
一、前言
对于从事后端开发的同学来说,线程是必须要使用了,因为使用它可以提升系统的性能。
但是,创建线程和销毁线程都是比较耗时的操作,频繁的创建和销毁线程会浪费很多CPU的资源。此外,如果每个任务都创建一个线程去处理,这样线程会越来越多。我们知道每个线程默认情况下占1M的内存空间,如果线程非常多,内存资源将会被耗尽。
这时,我们需要线程池去管理线程,不会出现内存资源被耗尽的情况,也不会出现频繁创建和销毁线程的情况,因为它内部是可以复用线程的。
二、从实战开始
在介绍线程池之前,让我们先看个例子。
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("MyCallable call");
return "success";
}
public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
try {
Future<String> future = threadPool.submit(new MyCallable());
System.out.println(future.get());
} catch (Exception e) {
System.out.println(e);
} finally {
threadPool.shutdown();
}
}
}
这个类的功能就是使用Executors类的newSingleThreadExecutor方法创建了的一个单线程池,他里面会执行Callable线程任务。
三、创建线程池的方法
我们仔细看看Executors类,会发现它里面给我们封装了不少创建线程池的静态方法,如下图所示:
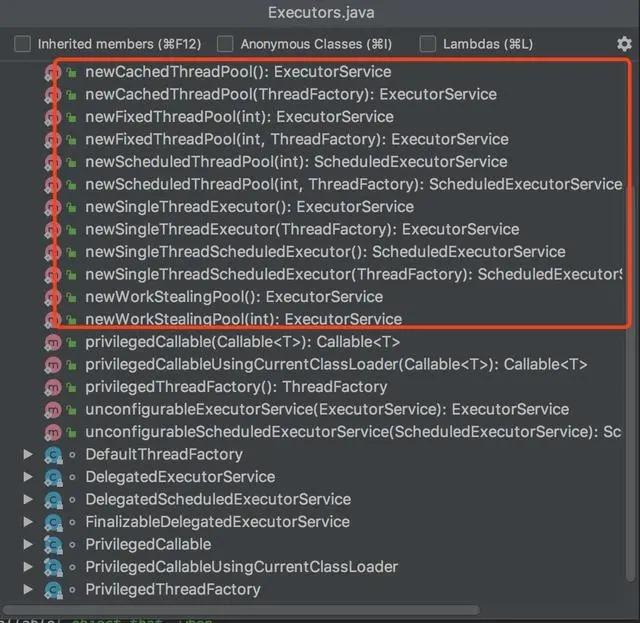
其实,我们总结一下其实只有6种:
1.newCachedThreadPool可缓冲线程池
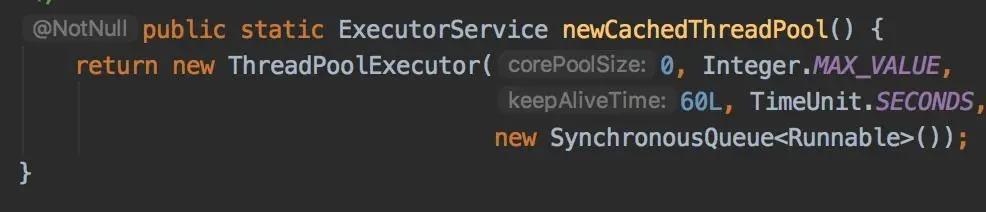
它的核心线程数是0,最大线程数是integer的最大值,每隔60秒回收一次空闲线程,使用SynchronousQueue队列。SynchronousQueue队列比较特殊,内部只包含一个元素,插入元素到队列的线程被阻塞,直到另一个线程从队列中获取了队列中存储的元素。同样,如果线程尝试获取元素并且当前不存在任何元素,则该线程将被阻塞,直到线程将元素插入队列。
2.newFixedThreadPool固定大小线程池

它的核心线程数 和 最大线程数是一样,都是nThreads变量的值,该变量由用户自己决定,所以说是固定大小线程池。此外,它的每隔0毫秒回收一次线程,换句话说就是不回收线程,因为它的核心线程数 和 最大线程数是一样,回收了没有任何意义。此外,使用了LinkedBlockingQueue队列,该队列其实是有界队列,很多人误解了,只是它的初始大小比较大是integer的最大值。
3.newScheduledThreadPool定时任务线程池

它的核心线程数是corePoolSize变量,需要用户自己决定,最大线程数是integer的最大值,同样,它的每隔0毫秒回收一次线程,换句话说就是不回收线程。使用了DelayedWorkQueue队列,该队列具有延时的功能。
4.newSingleThreadExecutor单个线程池
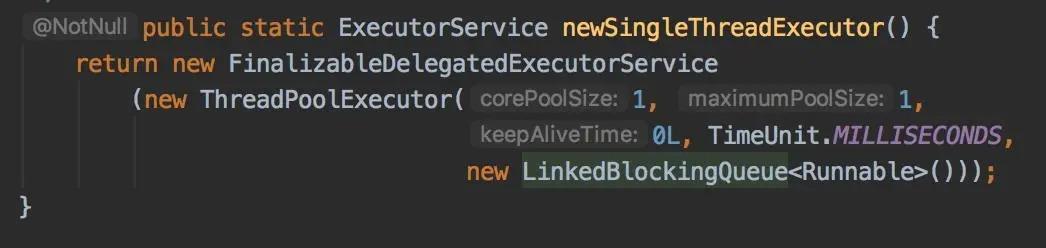
其实,跟上面的newFixedThreadPool是一样的,稍微有一点区别是核心线程数 和 最大线程数 都是1,这就是为什么说它是单线程池的原因。
5.newSingleThreadScheduledExecutor单线程定时任务线程池

该线程池是对上面介绍过的ScheduledThreadPoolExecutor定时任务线程池的简单封装,核心线程数固定是1,其他的功能一模一样。
6.newWorkStealingPool窃取线程池
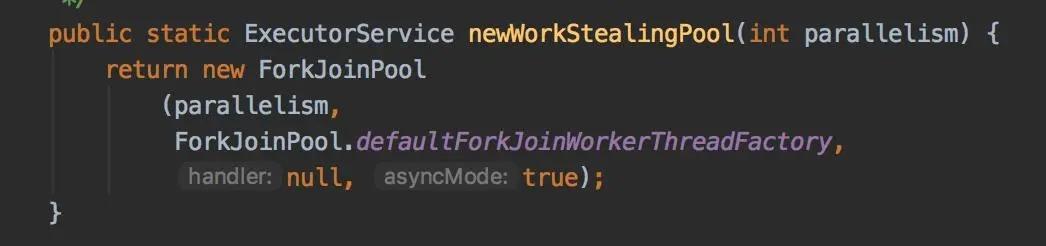
它是JDK1.8增加的新线程池,跟其他的实现方式都不一样,它底层是通过ForkJoinPool类来实现的。会创建一个含有足够多线程的线程池,来维持相应的并行级别,它会通过工作窃取的方式,使得多核的 CPU 不会闲置,总会有活着的线程让 CPU 去运行。
讲了这么多,具体要怎么用呢?
其实newFixedThreadPool、newCachedThreadPool、newSingleThreadExecutor 和 newWorkStealingPool方法创建和使用线程池的方法是一样的。这四个方法创建线程池返回值是ExecutorService,通过它的execute方法执行线程。
public class MyWorker implements Runnable {
@Override
public void run() {
System.out.println("MyWorker run");
}
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(8);
try {
threadPool.execute(new MyWorker());
} catch (Exception e) {
System.out.println(e);
} finally {
threadPool.shutdown();
}
}
}
newScheduledThreadPool 和 newSingleThreadScheduledExecutor 方法创建和使用线程池的方法也是一样的
public class MyTask implements Runnable {
@Override
public void run() {
System.out.println("MyTask call");
}
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(8);
try {
scheduledExecutorService.schedule(new MyRunnable(), 60, TimeUnit.SECONDS);
} finally {
scheduledExecutorService.shutdown();
}
}
}
以上两个方法创建的线程池返回值是ScheduledExecutorService,通过它的schedule提交线程,并且可以配置延迟执行的时间。
四、自定义线程池
Executors类有这么多方法可以创建线程池,但是阿里巴巴开发规范中却明确规定不要使用Executors类创建线程池,这是为什么呢?
newCachedThreadPool可缓冲线程池,它的最大线程数是integer的最大值,意味着使用它创建的线程池,可以创建非常多的线程,我们都知道一个线程默认情况下占用内存1M,如果创建的线程太多,占用内存太大,最后肯定会出现内存溢出的问题。
newFixedThreadPool和newSingleThreadExecutor在这里都称为固定大小线程池,它的队列使用的LinkedBlockingQueue,我们都知道这个队列默认大小是integer的最大值,意味着可以往该队列中加非常多的任务,每个任务也是要内存空间的,如果任务太多,最后肯定也会出现内存溢出的问题。
阿里建议使用ThreadPoolExecutor类创建线程池,其实从刚刚看到的Executors类创建线程池的newFixedThreadPool等方法可以看出,它也是使用ThreadPoolExecutor类创建线程池的。

从上图可以看出ThreadPoolExecutor类的构造方法有4个,里面包含了很多参数,让我们先一起认识一下:
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数
- keepAliveTime:空闲线程回收时间间隔
- unit:空闲线程回收时间间隔单位
- workQueue:提交任务的队列,当线程数量超过核心线程数时,可以将任务提交到任务队列中。比较常用的有:ArrayBlockingQueue; LinkedBlockingQueue; SynchronousQueue;
- threadFactory:线程工厂,可以自定义线程的一些属性,比如:名称或者守护线程等
- handler:表示当拒绝处理任务时的策略 > AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 DiscardPolicy:也是丢弃任务,但是不抛出异常。 DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程) CallerRunsPolicy:由调用线程处理该任务
我们根据上面的内容自定义一个线程池:
public class MyThreadPool implements Runnable {
private static final ExecutorService executorService = new ThreadPoolExecutor(
8,
10,
30,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(500),
new ThreadPoolExecutor.AbortPolicy());
@Override
public void run() {
System.out.println("MyThreadPool run");
}
public static void main(String[] args) {
int availableProcessors = Runtime.getRuntime().availableProcessors();
try {
executorService.execute(new MyThreadPool());
} catch (Exception e) {
System.out.println(e);
} finally {
executorService.shutdown();
}
}
}
从上面可以看到,我们使用ThreadPoolExecutor类自定义了一个线程池,它的核心线程数是8,最大线程数是 10,空闲线程回收时间是30,单位是秒,存放任务的队列用的ArrayBlockingQueue,而队列满的处理策略用的AbortPolicy。使用这个队列,基本可以保持线程在系统的可控范围之内,不会出现内存溢出的问题。但是也不是绝对的,只是出现内存溢出的概率比较小。
当然,阿里巴巴开发规范建议不使用Executors类创建线程池,并不表示它完全没用,在一些低并发的业务场景照样可以使用。
五、最佳线程数
在使用线程池时,很多同学都有这样的疑问,不知道如何配置线程数量,今天我们一起探讨一下这个问题。
1.经验值
配置线程数量之前,首先要看任务的类型是 IO密集型,还是CPU密集型?
什么是IO密集型?
比如:频繁读取磁盘上的数据,或者需要通过网络远程调用接口。
什么是CPU密集型?
比如:非常复杂的调用,循环次数很多,或者递归调用层次很深等。
IO密集型配置线程数经验值是:2N,其中N代表CPU核数。
CPU密集型配置线程数经验值是:N + 1,其中N代表CPU核数。
如果获取N的值?
int availableProcessors = Runtime.getRuntime().availableProcessors();
那么问题来了,混合型(既包含IO密集型,又包含CPU密集型)的如何配置线程数?
混合型如果IO密集型,和CPU密集型的执行时间相差不太大,可以拆分开,以便于更好配置。如果执行时间相差太大,优化的意义不大,比如IO密集型耗时60s,CPU密集型耗时1s。
2.最佳线程数目算法
除了上面介绍是经验值之外,其实还提供了计算公式:
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
很显然线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
虽说最佳线程数目算法更准确,但是线程等待时间和线程CPU时间不好测量,实际情况使用得比较少,一般用经验值就差不多了。再配合系统压测,基本可以确定最适合的线程数。
你可能感兴趣的文章
热门推荐
-
2、 - 优质文章
-
3、 gate.io
-
8、 golang
-
9、 openharmony
-
10、 Vue中input框自动聚焦