迷茫了,我们到底该不该用lombok?
迷茫了,我们到底该不该用lombok?
前言
最近上网查资料发现很多人对lombok褒贬不一,引起了我的兴趣,因为我们项目中也在大量使用lombok,大家不同的观点让我也困惑了几天,今天结合我实际的项目经验,说说我的个人建议。
随便搜搜就找到了这几篇文章:图片



这些人建议使用 lombok,觉得它是一个神器,可以大大提高编码效率,并且让代码更优雅。
在搜索的过程中,有些文章却又不推荐使用:图片



这些人觉得它有一些坑,容易给项目埋下隐患,我们到底该听谁的呢?
为什么建议使用lombok?
1.传统javabean
在没使用lombok之前,我们一般是这样定义javabean的:
public class User {
private Long id;
private String name;
private Integer age;
private String address;
public User() {
}
public User(Long id, String name, Integer age, String address) {
this.id = id;
this.name = name;
this.age = age;
this.address = address;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
public String getAddress() {
return address;
}
public void setId(Long id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void setAge(Integer age) {
this.age = age;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public boolean equals(Object o) {
if (this == o) returntrue;
if (o == null || getClass() != o.getClass()) returnfalse;
User user = (User) o;
return Objects.equals(id, user.id) &&
Objects.equals(name, user.name) &&
Objects.equals(age, user.age) &&
Objects.equals(address, user.address);
}
@Override
public int hashCode() {
return Objects.hash(id, name, age, address);
}
@Override
public String toString() {
return"User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
}
该User类中包含了:成员变量、getter/setter方法、构造方法、equals、hashCode方法。
咋一看,代码还是挺多的。而且还有个问题,如果User类中的代码修改了,比如:age字段改成字符串类型,或者name字段名称修改了,是不是需要同步修改相关的成员变量、getter/setter方法、构造方法、equals、hashCode方法全都修改一遍?
也许有些朋友会说:现在的idea非常智能,可以把修改一次性搞定。
没错,但是有更优雅的处理方法。
2.lombok的使用
第一步,引入jar包
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.4</version>
<scope>provided</scope>
</dependency>
第二步,在idea中安装插件
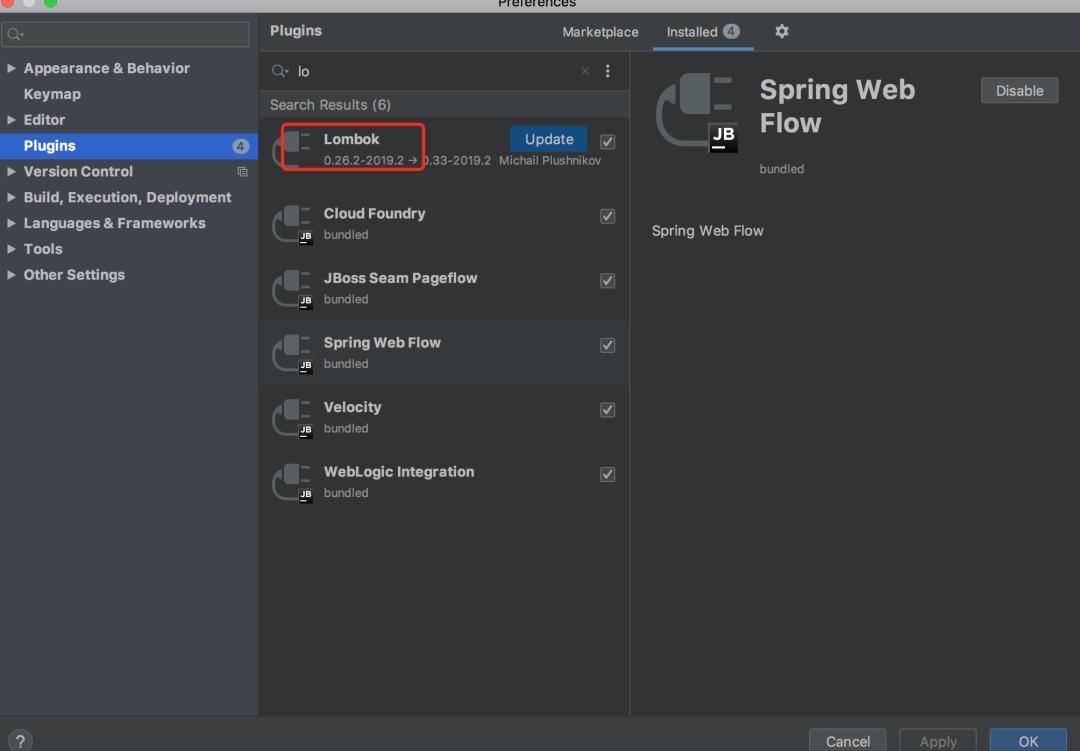
注意:如果不按照插件idea中就无法编译使用lombok注解的代码。
第三步,在代码中使用lombok注解
上面的User类代码可以改成这样:
@ToString
@EqualsAndHashCode
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Setter
publicclass User {
private Long id;
private String name;
private Integer age;
private String address;
}
so good,代码可以优化到如此简单。User类的主体只用定义成员变量,其他的方法全都交给注解来完成。
如果修改了成员变量名称或者类型,怎么办呢?
@ToString
@EqualsAndHashCode
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Setter
public class User {
private Long id;
private String userName;
private String age;
private String address;
}
你只用一心一意修改成员变量即可,其他的根本不用操心,简直太爽了。
更让人兴奋的是,还能进一步优化:
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User {
private Long id;
private String userName;
private String age;
private String address;
}
@Data相当于@Getter、@Setter、@ToString、@EqualsAndHashCode、@RequiredArgsConstructor的集合。
lombok注解整理如下:

图片来源占小狼
从上面看出使用lombok给人最大的感受是代码量显著减少了,能够有效的提升开发效率,而代码看起来更优雅,确实是一个不可多得的神器。
lombok工作原理
java程序的解析分为:运行时解析 和 编译时解析。
通常我们通过反射获取类、方法、注解和成员变量就是运行时解析。但是这种方式效率其实不高,要在程序运行起来才能解析。
这时候编译时解析就体现出它的价值了。
编译时解析又分为:注解处理器(Annotation Processing Tool)和JSR 269 插入式注解处理器(Pluggable Annotation Processing API)
第一种处理器它最早是在 JDK 1.5 与注解(Annotation) 一起引入的,它是一个命令行工具,能够提供构建时基于源代码对程序结构的读取功能,能够通过运行注解处理器来生成新的中间文件,进而影响编译过程。
不过在JDK 1.8以后,第一种处理器被淘汰了,取而代之的是第二种处理器,我们一起看看它的处理流程:
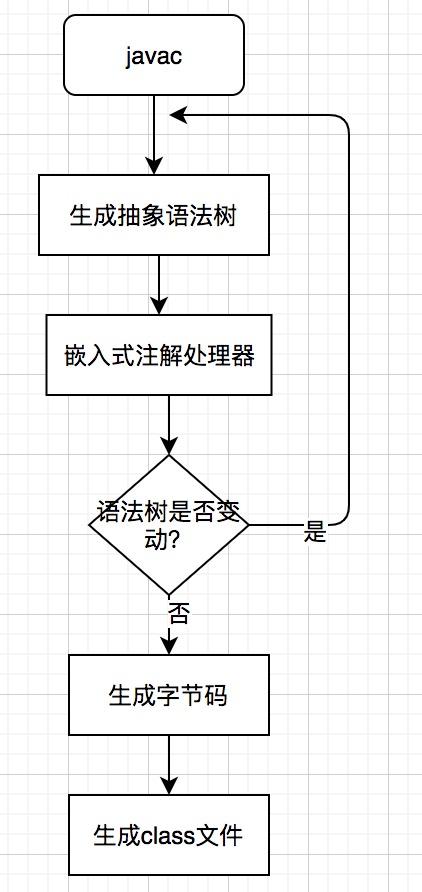
Lombok的底层具体实现流程如下:
- javac对源代码进行分析,生成了一棵抽象语法树(AST)
- 编译过程中调用实现了“JSR 269 API”的Lombok程序
- 此时Lombok就对第一步骤得到的AST进行处理,找到@Data注解所在类对应的语法树(AST),然后修改该语法树(AST),增加getter和setter方法定义的相应树节点
- javac使用修改后的抽象语法树(AST)生成字节码文件,即给class增加新的节点(代码块)
为什么建议不用lombok?
即使lombok是一个神器,但是却有很多人不建议使用,这又是为什么呢?
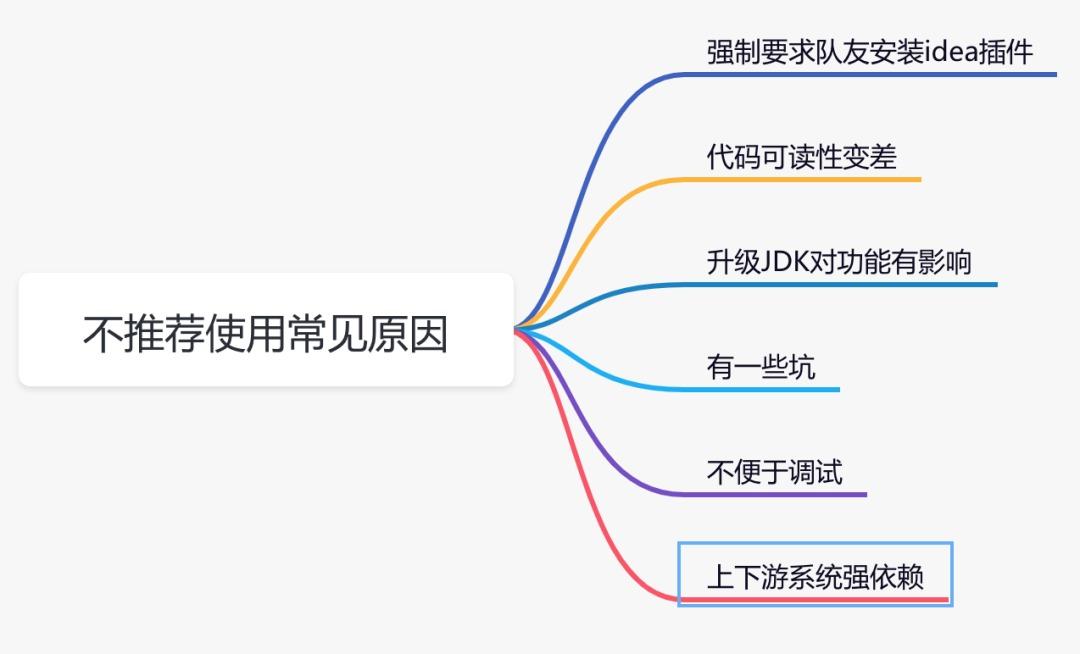
1.强制要求队友安装idea插件
这点确实比较恶心,因为如果使用lombok注解编写代码,就要求参与开发的所有人都必须安装idea的lombok插件,否则代码编译出错。
2.代码可读性变差
使用lombok注解之后,最后生成的代码你其实是看不到的,你能看到的是代码被修改之前的样子。如果要想查看某个getter或setter方法的引用过程,是非常困难的。
3.升级JDK对功能有影响
有人把JDK从Java 8升级到Java 11时,后发现Lombok不能正常工作了。
4.有一些坑
使用@Data时会默认使用@EqualsAndHashCode(callSuper=false),这时候生成的equals()方法只会比较子类的属性,不会考虑从父类继承的属性,无论父类属性访问权限是否开放。
使用@Builder时要加上@AllArgsConstructor,否则可能会报错。
5.不便于调试
我们平时大部分人都喜欢用debug调试定位问题,但是使用lombok生成的代码不太好调试。
6.上下游系统强依赖
如果上游系统中提供的fegin client使用了lombok,那么下游系统必须也使用lombok,否则会报错,上下游系统构成了强依赖。
我们该如何选择?
lombok有利有弊,我们该如何选择呢?
个人建议要结合项目的实际情况做最合理的选择。
- 如果你参与的是一个新项目,上下游系统都是新的,这时候建议使用lombok,因为它可以显著提升开发效率。
- 如果你参与的是一个老项目,并且以前没有使用过lombok,建议你后面也不要使用,因为代码改造成本较高。如果以前使用过lombok,建议你后面也使用,因为代码改造成本较高。
- 其实只要引入jar包可能都有:强制要求队友安装idea插件、升级JDK对功能有影响、有一些坑 和 上下游系统强依赖 这几个问题,只要制定好规范,多总结使用经验这些问题不大。
- 代码的可读性变差 和 不便于调试 这两个问题,我认为也不大,因为lombok一般被使用在javabean上,该类的逻辑相对来说比较简单,很多代码一眼就能看明白,即使不调试问题原因也能猜测7、8分。
你可能感兴趣的文章
热门推荐
-
2、 - 优质文章
-
3、 gate.io
-
8、 golang
-
9、 openharmony
-
10、 Vue中input框自动聚焦