Redis缓存穿透-布隆过滤器
Redis缓存穿透-布隆过滤器
缓存穿透
我举个蘑菇博客中的案例来说,我现在有一个博客详情页,然后博客详情页中的内容假设是存储在Redis中的,然后通过博客的Uid进行获取,正常的情况是:用户进入博客详情页,然后通过uid获取redis中缓存的文章详情,如果有内容就直接访问,如果不存在内容,那么需要访问数据库,然后从数据库中查询我们的博客详情后,然后在存储到redis中,最后在把数据返回给我们的页面。
但是可能存在一些非法用户,他可能会模拟出很多不存在的key,然后通过该key去请求后台,首先redis的缓存没有命中,那么就去请求数据库,最后数据库没有查询出该内容,这样很多个非法的请求直接打在数据库中,可能会导致数据库直接宕机,无法对外提供服务。这就是我们所说的缓存穿透问题
简单的解决方法
针对这个情况,我们有一种简单的解决方法就是,在数据库没有查询该条数据的时候,我们让该key缓存一个 空数据,这样用户再次以该key请求后台的时候,会直接返回null,避免了再次请求数据库。
布隆过滤器
什么是布隆过滤器?
布隆过滤器的巨大作用 ,就是能够迅速判断一个元素是否存在一个集合中。因此次他有如下几个使用场景
- 网站爬虫对URL的去重,避免爬取相同的URL
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否是垃圾邮件(同理,垃圾短信)
- 缓存穿透,将所有可能的数据缓存放到布隆过滤器中,当黑客访问不存在的缓存时,迅速返回避免缓存以及DB挂掉。
原理
布隆过滤器其内部维护了一个全为0的bit数组,需要说明的是,布隆过滤器有一个误判的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间多少。
假设,根据误判率,我们生成一个10位的bit数组,以及2个hash函数 f1 和 f2,如下图所示:生成的数组的位数 和 hash函数的数量,我们不用去关心如何生成的,这是有数学论文进行验证。
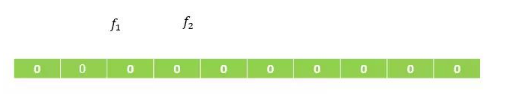
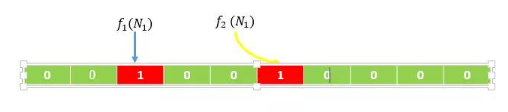
然后我们输入一个集合,集合中包含 N1 和 N2,我们通过计算 f1(N1) = 2,f2(N1) = 5,则将数组下标为2 和下标为5的位置设置成1,就得到了下图
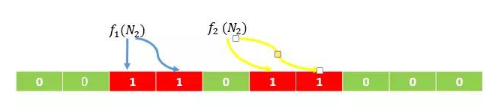
同理,我们再次进行计算 N2的值, f1(N2) = 3,f2(N2) = 6。得到如下所示的图
这个时候,假设我们有第三个数N3过来了,我们需要判断N3是否在集合 [N1,N2]中,我们需要做的操作就是,使用f1 和 f2 计算出数组中的地址
- 若值恰巧都位于上图的红色位置,我们认为 N3在集合 [N1,N2] 中
- 若值有一个不位于上图的红色部分,我们认为N3不在集合[N1,N2] 中
这就是布隆过滤器的计算原理
使用
在java中使用布隆过滤器,我们需要首先引入依赖,布隆过滤器拥有Google提供的一个开箱即用的组件,来帮助我们实现布隆过滤器,其实布隆过滤器的核心思想其实并不难,难的是在于如何设计随机映射函数,到底映射几次,二进制向量设置多少比较合适。
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
</dependencies>
然后我们编写代码,测试某元素是否存在于百万元素集合中
private static int size = 1000000;//预计要插入多少数据
private static double fpp = 0.01;//期望的误判率
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
//插入数据
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
int count = 0;
for (int i = 1000000; i < 2000000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);
}
代码分析
上面的代码中,我们创建了一个布隆过滤器,其中有两个重要的参数,分别是我们要预计插入的数据和我们所期望的误判率,误判率率不能为0。
我们首先向布隆过滤器中插入 0 ~ 100万条数据,然后在用 100万 ~ 200万的数据进行测试
我们输出结果,查看一下误判率
1999501误判了
1999567误判了
1999640误判了
1999697误判了
1999827误判了
1999942误判了
总共的误判数:10314
现在有100万不存在的数据,误判了10314次,我们计算一下误判率
10314 / 1000000 = 0.010314
和我们之前定义的误判率为0.01相差无几
参考
https://www.cnblogs.com/rinack/p/9712477.html
https://www.jianshu.com/p/2104d11ee0a2
https://www.cnblogs.com/CodeBear/p/10911177.html
你可能感兴趣的文章
热门推荐
-
2、 - 优质文章
-
3、 gate.io
-
8、 golang
-
9、 openharmony
-
10、 Vue中input框自动聚焦