java-collection-questions-02
title: Java集合常见面试题总结(下) category: Java tag: - Java集合 head: - - meta - name: keywords content: HashMap,ConcurrentHashMap,Hashtable,List,Set - - meta - name: description
content: Java集合常见知识点和面试题总结,希望对你有帮助!
Map 接口
HashMap 和 Hashtable 的区别
- 线程是否安全:
HashMap是非线程安全的,Hashtable是线程安全的,因为Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!); - 效率: 因为线程安全的问题,
HashMap要比Hashtable效率高一点。另外,Hashtable基本被淘汰,不要在代码中使用它; - 对 Null key 和 Null value 的支持:
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出NullPointerException。 - 初始容量大小和每次扩充容量大小的不同 : ① 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为 2 的幂次方大小(HashMap中的tableSizeFor()方法保证,下面给出了源代码)。也就是说HashMap总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。 - 底层数据结构: JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。Hashtable没有这样的机制。
HashMap 中带有初始容量的构造函数:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
下面这个方法保证了 HashMap 总是使用 2 的幂作为哈希表的大小。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap 和 HashSet 区别
如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone()、writeObject()、readObject()是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
HashMap |
HashSet |
|---|---|
实现了 Map 接口 |
实现 Set 接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向 map 中添加元素 |
调用 add()方法向 Set 中添加元素 |
HashMap 使用键(Key)计算 hashcode |
HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性 |
HashMap 和 TreeMap 区别
TreeMap 和HashMap 都继承自AbstractMap ,但是需要注意的是TreeMap它还实现了NavigableMap接口和SortedMap 接口。
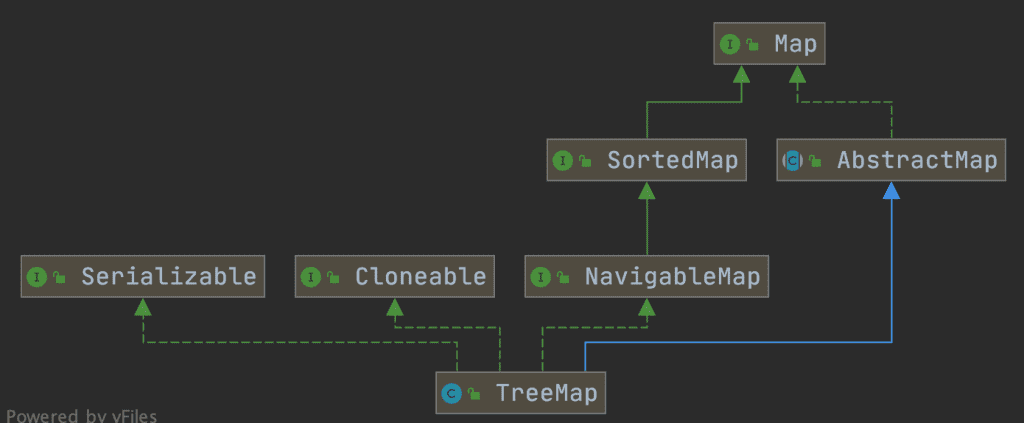
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
实现SortedMap接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。示例代码如下:
/**
* @author shuang.kou
* @createTime 2020年06月15日 17:02:00
*/
public class Person {
private Integer age;
public Person(Integer age) {
this.age = age;
}
public Integer getAge() {
return age;
}
public static void main(String[] args) {
TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person person1, Person person2) {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
}
});
treeMap.put(new Person(3), "person1");
treeMap.put(new Person(18), "person2");
treeMap.put(new Person(35), "person3");
treeMap.put(new Person(16), "person4");
treeMap.entrySet().stream().forEach(personStringEntry -> {
System.out.println(personStringEntry.getValue());
});
}
}
输出:
person1
person4
person2
person3
可以看出,TreeMap 中的元素已经是按照 Person 的 age 字段的升序来排列了。
上面,我们是通过传入匿名内部类的方式实现的,你可以将代码替换成 Lambda 表达式实现的方式:
TreeMap<Person, String> treeMap = new TreeMap<>((person1, person2) -> {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
});
综上,相比于HashMap来说 TreeMap 主要多了对集合中的元素根据键排序的能力以及对集合内元素的搜索的能力。
HashSet 如何检查重复
以下内容摘自我的 Java 启蒙书《Head first java》第二版:
当你把对象加入HashSet时,HashSet 会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让加入操作成功。
在openjdk8中,HashSet的add()方法只是简单的调用了HashMap的put()方法,并且判断了一下返回值以确保是否有重复元素。直接看一下HashSet中的源码:
// Returns: true if this set did not already contain the specified element
// 返回值:当set中没有包含add的元素时返回真
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
而在HashMap的putVal()方法中也能看到如下说明:
// Returns : previous value, or null if none
// 返回值:如果插入位置没有元素返回null,否则返回上一个元素
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
}
也就是说,在openjdk8中,实际上无论HashSet中是否已经存在了某元素,HashSet都会直接插入,只是会在add()方法的返回值处告诉我们插入前是否存在相同元素。
hashCode()与 equals() 的相关规定:
- 如果两个对象相等,则
hashcode一定也是相同的 - 两个对象相等,对两个
equals()方法返回 true - 两个对象有相同的
hashcode值,它们也不一定是相等的 - 综上,
equals()方法被覆盖过,则hashCode()方法也必须被覆盖 hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
==与 equals 的区别
对于基本类型来说,== 比较的是值是否相等;
对于引用类型来说,== 比较的是两个引用是否指向同一个对象地址(两者在内存中存放的地址(堆内存地址)是否指向同一个地方);
对于引用类型(包括包装类型)来说,equals 如果没有被重写,对比它们的地址是否相等;如果 equals()方法被重写(例如 String),则比较的是地址里的内容。
HashMap 的底层实现
JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
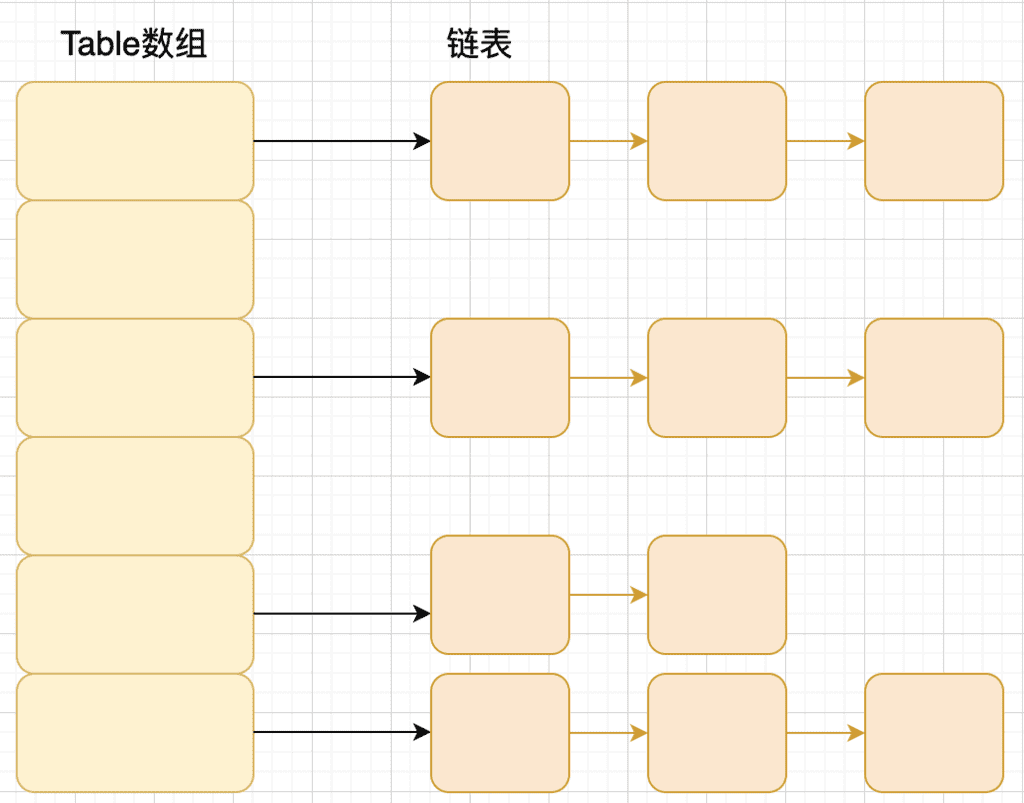
JDK1.8 之后
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
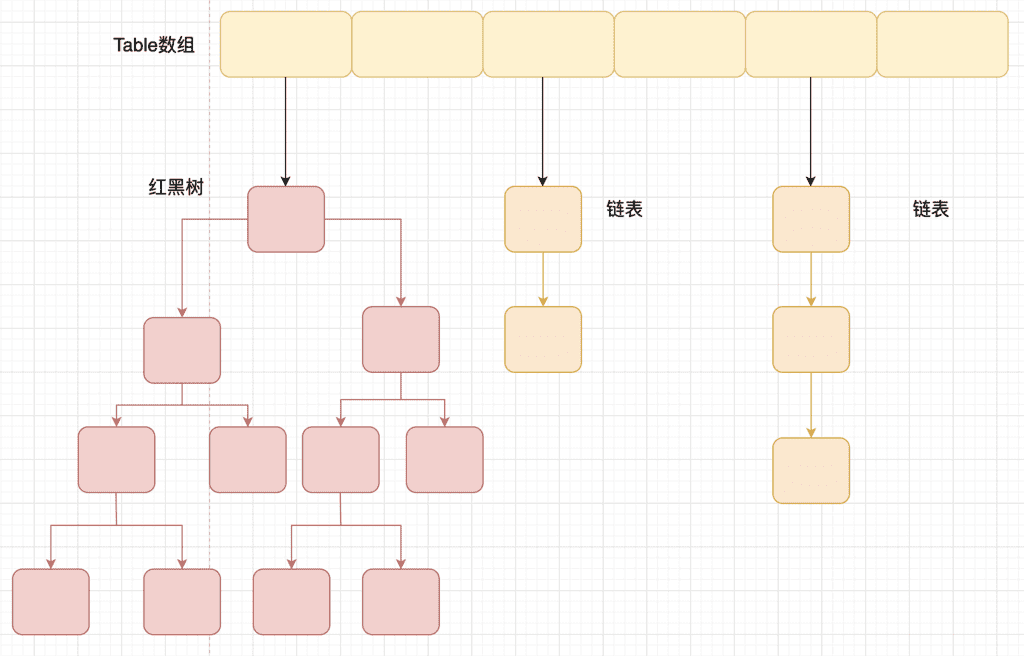
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
我们来结合源码分析一下 HashMap 链表到红黑树的转换。
1、 putVal 方法中执行链表转红黑树的判断逻辑。
链表的长度大于 8 的时候,就执行 treeifyBin (转换红黑树)的逻辑。
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 遍历到链表最后一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表元素个数大于等于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 红黑树转换(并不会直接转换成红黑树)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
2、treeifyBin 方法中判断是否真的转换为红黑树。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 判断当前数组的长度是否小于 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 如果当前数组的长度小于 64,那么会选择先进行数组扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 否则才将列表转换为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树。
HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
HashMap 多线程操作导致死循环问题
主要原因在于并发下的 Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
详情请查看:https://coolshell.cn/articles/9606.html
HashMap 有哪几种常见的遍历方式?
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的
ConcurrentHashMap底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable和 JDK1.8 之前的HashMap的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的; - 实现线程安全的方式(重要): ① 在 JDK1.7 的时候,
ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后 对synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本;②Hashtable(同一把锁) :使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
两者的对比图:
Hashtable:
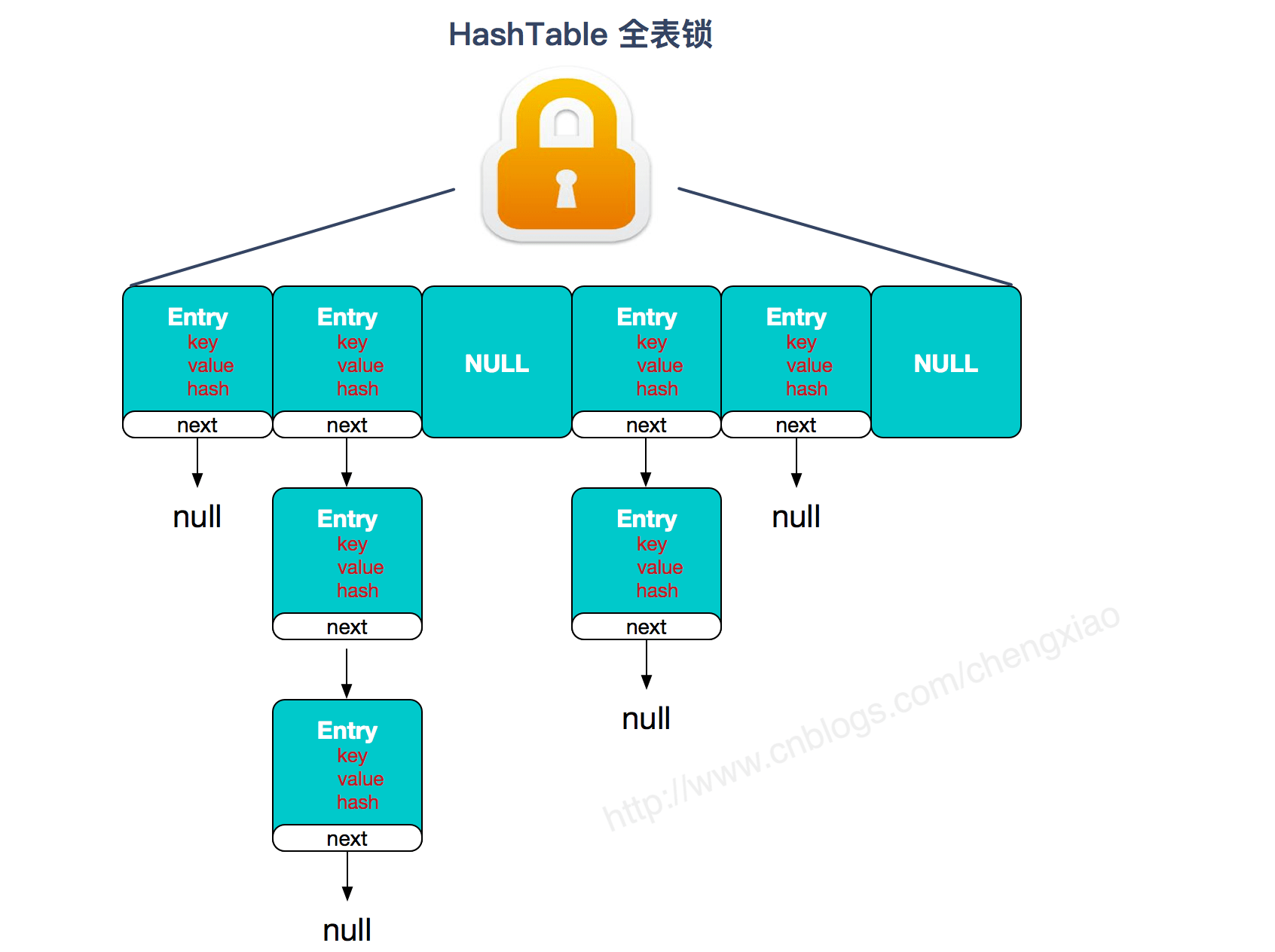
https://www.cnblogs.com/chengxiao/p/6842045.html>
JDK1.7 的 ConcurrentHashMap:
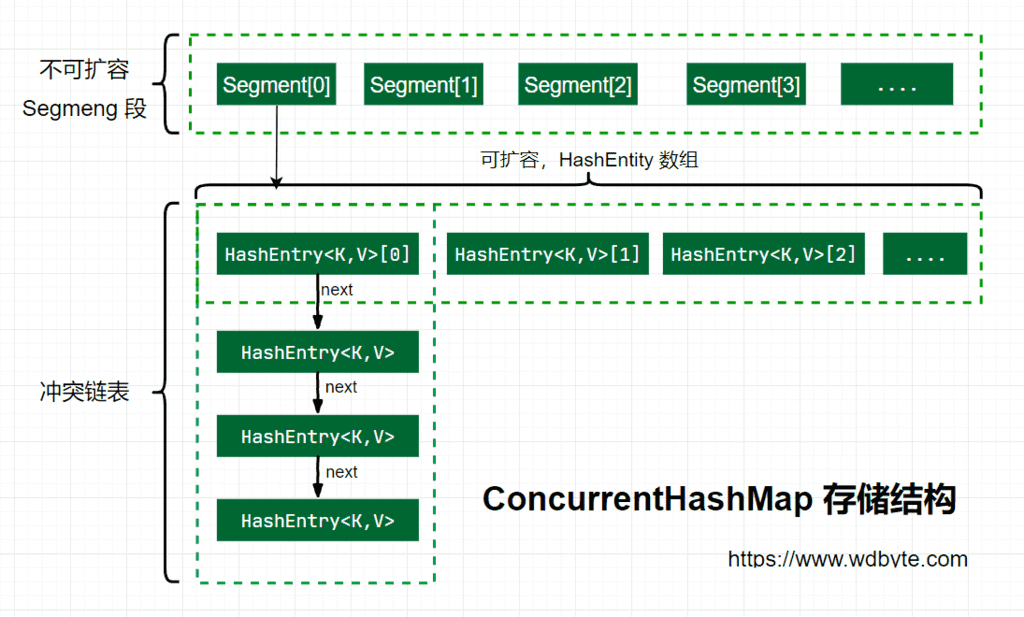
JDK1.8 的 ConcurrentHashMap:
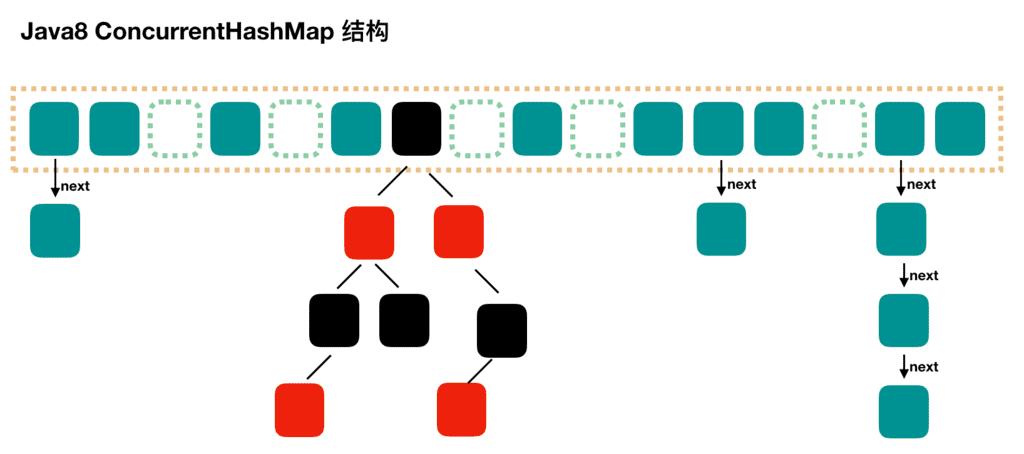
JDK1.8 的 ConcurrentHashMap 不再是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。
ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
JDK1.7(上面有示意图)
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
JDK1.8 (上面有示意图)
ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
Collections 工具类
Collections 工具类常用方法:
- 排序
- 查找,替换操作
- 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
排序操作
void reverse(List list)//反转
void shuffle(List list)//随机排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j)//交换两个索引位置的元素
void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面
查找,替换操作
int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素
int frequency(Collection c, Object o)//统计元素出现次数
int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target)
boolean replaceAll(List list, Object oldVal, Object newVal)//用新元素替换旧元素
同步控制
Collections 提供了多个synchronizedXxx()方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
我们知道 HashSet,TreeSet,ArrayList,LinkedList,HashMap,TreeMap 都是线程不安全的。Collections 提供了多个静态方法可以把他们包装成线程同步的集合。
最好不要用下面这些方法,效率非常低,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合。
方法如下:
synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(线程安全的)collection。
synchronizedList(List<T> list)//返回指定列表支持的同步(线程安全的)List。
synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)Map。
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。
相关文章
concurrent-hash-map-source-code
热门推荐
-
2、 - 优质文章
-
3、 gate.io
-
8、 golang
-
9、 openharmony
-
10、 Vue中input框自动聚焦